Post Syndicated from Andy Klein original https://www.backblaze.com/blog/open-source-data-storage-server/

Storage Pod 6.0 deploys 60 off-the-shelf hard drives in a 4U chassis to lower the cost of our latest data storage server to just $0.036/GB. That’s 22 percent less than our Storage Pod 5.0 storage server that used 45 drives to store data for $0.044/GB. The Storage Pod 6.0 hardware design is, as always, open source so we’ve included the blueprints, STEP files, wiring diagrams, build instructions and a parts list so you can build your very own Storage Pod. Your cost may be a bit more, but it is possible for you to build a 4U server with 480TB of data storage for less than a nickel ($0.05) a gigabyte – read on.
A little Storage Pod history
In 2009, Storage Pod 1.0 changed the landscape in data storage servers by delivering 67.5TB of storage in a 4U box for just $0.11/GB – that was up to 10 times lower than comparable systems on the market at the time. We also open-sourced the hardware design of Storage Pod 1.0 and companies, universities, and even weekend hobbyist started building their own Storage Pods.
Over the years we introduced updates to the Storage Pod design, driving down the cost while improving the reliability and durability with each iteration. Storage Pod 5.0 marked our initial use of the Agile manufacturing and design methodology which helped identify and squeeze out more costs, driving our cost per GB of storage below $0.05. Agile also enabled us to manage a rapid design prototyping process that allowed us stretch the Storage Pod chassis to include 60 drives then produce 2-D and 3-D specifications, a build book, a bill of materials and update our manufacturing and assembly processes for the new design – Storage Pod 6.0. All of this in about 6 months.
What’s new in Storage Pod 6.0

What’s new is 60 drives in a 4U chassis. That’s a 33 percent increase to the storage density in the same rack space. Using 4TB drives in a 60-drive Storage Pod increases the amount of storage in a standard 40U rack from 1.8 to 2.4 Petabytes. Of course, by using 8TB drives you’d get a 480TB data storage server in 4U server and 4.8 Petabytes in a standard rack.
When looking at what’s new in Storage Pod 6.0 it would easy to say it has 60 drives and stop there. After all, the Motherboard, CPU, memory, SATA cards, and backplanes we use didn’t change from 5.0. But expanding to 60 drives created all kinds of things to consider, for example:
- How long do you make the chassis before it is too long for the rack?
- Will we need more cooling?
- Will the power supplies need to be upgraded?
- Will the SATA cables be too long? The maximum spec’d length is 1 meter.
- Can the SATA cards keep up with the 15 more drives? Or will we need to upgrade them?
- Will the CPU and the motherboard be able to handle the additional data load of 15 more drives?
- Will more or faster memory be required?
- Will the overall Storage Pod be correctly balanced between CPU, memory, storage and other components so that nothing is over/under-spec’ed?
- What hard drives will work with this configuration? Would we have to use enterprise drives? Just kidding!
Rapidly iterating to the right design
As part of the prototyping effort we built multiple configurations and Backblaze Labs put each configuration through its paces. To do this we assembled a Backblaze Vault with 20 prototype Storage Pods in three different configurations. Since each Storage Pod in a Backblaze Vault is expected to perform similarly, we monitored and detected those Storage Pods that were lagging as well as those that were “bored”. By doing this were were able to determine that most of the components in Storage Pod 6.0 did not need to be upgraded to achieve optimal performanace in Backblaze Vaults utlizing 60 drive Storage Pods.
We did make some changes to Storage Pod 6.0 however:
- Increased the chassis by 5 ½” from 28 1/16” to 33 9/16” in length. Server racks are typically 29” in depth, more on that later.
- Increased the length of the backplane tray to support 12 backplanes.
- Added 1 additional drive bracket to handle another row of 15 drives.
- Added 3 more backplanes and 1 more SATA card.
- Added 3 more SATA cables.
- Changed the routing to of the SATA-3 cables to stay within the 1-meter length spec.
- Updated the pigtail cable design so we could power the three additional backplanes.
- Changed the routing of the power cables on the backplane tray.
- Changed the on/off switch retiring the ele-302 and replacing it with the Chill-22.
- Increased the length of the lid over the drive bay 22 7/8”.
That last item, increasing the length of the drive bay lid, led to a redesign of both lids. Why?

The lid from Storage Pod 5.0 (on the left above) proved to be difficult to remove when it was stretched another 4+ inches. The tabs didn’t provide enough leverage to easily open the longer drive lid. As a consequence Storage Pod 6.0 has a new design (shown on the right above) which provides much better leverage. The design in the middle was one of the prototype designs we tried, but in the end the “flame” kept catching the fingers of the ops folks when they opened or closed the lid.
Too long for the server rack?
The 6.0 chassis is 33 9/16” in length and 35 1/16” with the lids on. A rack is typically 29” in depth, leaving 4+ inches of Storage Pod chassis “hanging out.” We decided to keep the front (Backblaze logo side) aligned to the front of the rack and let the excess hang off the back in the warm aisle of the datacenter. A majority of a pod’s weight is in the front (60 drives!) so the rails support this weight. The overhang is on the back side of the rack, but there’s plenty of room between the rows of racks, so there’s no issue with space. We’re pointing out the overhang so if you end up building your own Storage Pod 6.0 server, you’ll leave enough space behind, or in front, of your rack for the overhang.
The cost in dollars
There are actually three different prices for a Storage Pod. Below are the costs of each of these scenarios to build a 180TB Storage Pod 6.0 storage server with 4TB hard drives:
| How Built | Total Cost | Description |
|---|---|---|
| Backblaze | $8,733.73 | The cost for Backblaze given that we purchase 500+ Storage Pods and 20,000+ hard drives per year. This includes materials, assembly, and testing. |
| You Build It | $10,398.57 | The cost for you to build one Storage Pod 6.0 server by buying the parts and assembling it yourself. |
| You Buy It | $12,849.40 | The cost for you to purchase one already assembled Storage Pod 6.0 server from a third-party supplier and then purchase and install 4TB hard drives yourself. |
| These prices do not include packaging, shipping, taxes, VAT, etc. | ||
Since we increased the number of drives from 45 to 60, comparing the total cost of Storage Pod 6.0 to previous the 45-drive versions isn’t appropriate. Instead we can compare them using the “Cost per GB” of storage.
The Cost per GB of storage
Using the Backblaze cost for comparison, below is the Cost per GB of building the different Storage Pod versions.

As you can see in the table, the cost in actual dollars increased by $760 with Storage Pod 6.0, but the Cost per GB decreased nearly a penny ($0.008) given the increased number of drives and some chassis design optimizations.
Saving $0.008 per GB may not seem very innovative, but think about what happens when that trivial amount is multiplied across the hundreds of Petabytes of data our B2 Cloud Storage service will store over the coming months and years. A little innovation goes a long way.
Building your own Storage Pod 6.0 server
You can build your own Storage Pod. Here’s what you need to get started:
Chassis – We’ve provided all the drawings you should need to build (or to have built) your own chassis. We’ve had multiple metal bending shops use these files to make a Storage Pod chassis. You get to pick the color.
- 2-D Blueprints – ZIP file: 4.6 MB
- 3-D Solidworks files – ZIP file: 112.0 MB
- STEP files – ZIP file: 26.6 MB
- Drive Guide design files – ZIP file: 606 KB
Parts – In Appendix A we’ve listed all the parts you’ll need for a Storage Pod. Most of the parts can be purchased online via Amazon, Newegg, etc. As noted on the parts list, some parts are purchased either through a distributor or from the contract assemblers.
- Storage Pod 6.0 Parts List – PDF file: 49 KB
Wiring – You can purchase the power wiring harness and pigtails as noted on the parts list, but you can also build your own. Whether you build or buy, you’ll want to download the instructions on how to route the cables in the backplane tray.
- Wiring Diagrams – ZIP file: 537 KB
- Wiring Routes – ZIP file: 37.0 KB
Build Book – Once you’ve gathered all the parts, you’ll need the Build Book for step-by-step assembly instructions.
- Build Book – PDF file: 20.8MB
As a reminder, Backblaze does not sell Storage Pods, and the design is open source, so we don’t provide support or warranty for people who choose to build their own Storage Pod. That said, if you do build your own, we’d like to hear from you.
Building a 480TB Storage Pod for less than a $0.05 per GB
We’ve used 4TB drives in this post for consistency, but we have in fact built Storage Pods with 5-, 6- and even 8-TB drives. If you are building a Storage Pod 6.0 storage server, you can certainly use higher capacity drives. To make it easy, the chart below is your estimated cost if you were to build your own Storage Pod using the drives noted. We used the lowest “Street Price” from Amazon or Newegg for the price of the 60 hard drives. The list is sorted by the Cost per GB (lowest to highest). The (*) indicates we use this drive model in our datacenter.
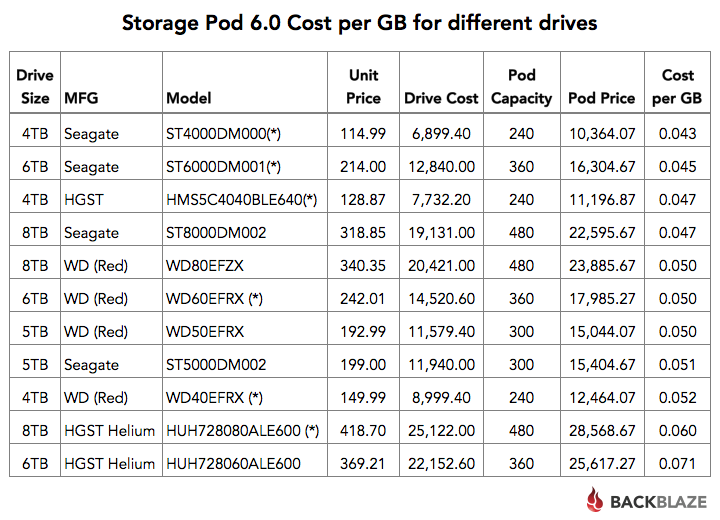
As you can see there are multiple drive models and capacities you can use to achieve a Cost per GB of $0.05 or less. Of course we aren’t counting your sweat-equity in building a Storage Pod, nor do we include the software you are planning to run. If you are looking for capacity, think about using the Seagate 8TB drives to get nearly a half a petabyte of storage in a 4U footprint (albeit with a 4” overhang) for just $0.047 a GB. Total cost: $22,600.
What about SMR drives?
Depending on your particular needs, you might consider using SMR hard drives. An SMR drive stores data more densely on each disk platter surface by “overlapping” tracks of data. This lowers the cost to store data. The downside is that when data is deleted, the newly freed space can be extremely slow to reuse. As such SMR drives are generally used for archiving duties where data is written sequentially to a drive with few, and preferably no, deletions. If this type of capability fits your application, you will find SMR hard drives to very inexpensive. For example, a Seagate 8TB Archive drive (model: ST8000AS0002) is $214.99, making the total cost for a 480TB Storage Pod 6.0 storage server only $16,364.07 or a very impressive $0.034 per GB. By the way, if you’re looking for off-site data archive storage, Backblaze B2 will store your data for just $0.005/GB/month.
Buying a Storage Pod
Backblaze does not sell Storage Pods or parts. If you are interested in buying a Storage Pod 6.0 storage server (without drives), you can check out the folks at Backuppods. They have partnered with Evolve Manufacturing to deliver Backblaze-inspired Storage Pods. Evolve Manufacturing is the contract manufacturer used by Backblaze to manufacture and assemble Storage Pod versions 4.5, 5.0 and now 6.0. Backuppods.com offers a fully assembled and tested Storage Pod 6.0 server (less drives) for $5,950.00 plus shipping, handling and tax. They also sell older Storage Pod versions. Please check out their website for the models and configurations they are currently offering.
Appendix A: Storage Pod 6.0 Parts List
Below is the list of parts you’ll need to build your own Storage Pod 6.0. The prices listed are “street” prices. You should be able to find these items online or from the manufacturer in quantities sufficient to build one Storage Pod. Good luck and happy building.
Includes case, supports, trays, etc.
EVGA Supernova NEX750G
Primochill 120-G1-0750-XR (Chill-22)
FAN AXIAL 120X25MM VAPO 12VDC
Power Supply Vibration Dampener
AFM03B (2 tab ends)
Supermicro MBD-X9SRH-7TF-O (MicroATX)
DYNATRON R13 1U Server CPU FAN
Intel XEON E5 -1620 V2 (Quad Core)
PC3-12800 DDR3-1600MHz 240-Pin
5 Port Backplane (Marvell 9715 chipset)
4-post PCIe Express (Marvell 9235 chipset)
SATA cables RA-to-STR 1M locking
24-pin – Backblaze to Pigtail
20-pin – Backblaze to Pigtail
24-pin – EVGA NEX750G Connector
NOTES:
- May be able to be purchased from backuppods.com, price may vary.
- Sunrich and CFI make the recommended backplanes and Sunrich and Syba make the recommended SATA Cards.
- Nippon Labs makes the recommended SATA cables, but others may work.
- Sold in packages of 100, used 100 package price for Extended Cost.
The post Storage Pod 6.0: Building a 60 Drive 480TB Storage Server appeared first on Backblaze Blog | The Life of a Cloud Backup Company.










 Click here
Click here




 Internet provider Verizon recently submitted a response to the U.S. Copyright Office, which is
Internet provider Verizon recently submitted a response to the U.S. Copyright Office, which is 






 Playing old console games through browser-based emulators and spin-offs is a niche pastime of many dedicated gamers.
Playing old console games through browser-based emulators and spin-offs is a niche pastime of many dedicated gamers.






















